国内大模型训练面临的算力困局有望得到纾缓。面向大模型训练,就在今日,腾讯云正式发布新一代HCC(High-Performance Computing Cluster)高性能计算集群。
该计算集群的整体性能比过去提升了3倍,堪称国内目前性能最强的大模型计算集群。
据悉,该计算集群搭载NVIDIA H800 Tensor Core GPU,能够提供高性能、高带宽、低延迟的算力支撑。
而针对大模型训练,计算集群有着训练框架AngelPTM,该框架对内支持了腾讯混元大模型的训练,并在去年10的的万亿参数大模型训练中,成功将时间缩短了80%。
该集群采用腾讯云星星海自研服务器,搭载英伟达最新代次H800 GPU。
服务器之间采用业界最高的3.2T超高互联带宽,为大模型训练、自动驾驶、科学计算等提供高性能、高带宽和低延迟的集群算力。
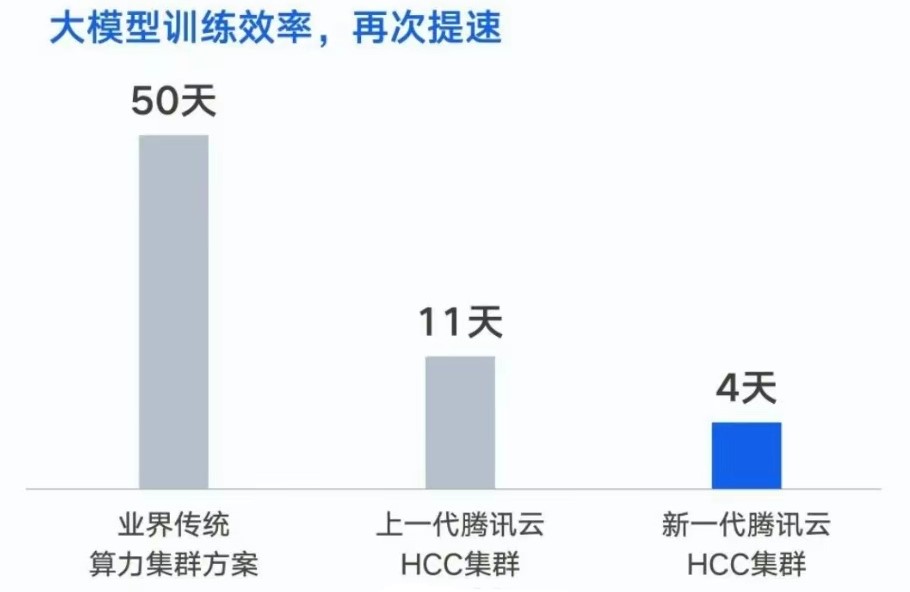
据腾讯介绍,实测显示,新一代集群整体性能比过去提升了3倍,是国内性能最强的大模型计算集群。
早在去年10月,腾讯训练框架AngelPTM,完成了首个万亿参数大模型训练——混元NLP大模型训练。
在同等数据集下,将训练时间由 50 天缩短到 11 天。如果基于新一代集群,训练时间将进一步缩短至 4 天。
前大热的人工智能大模型,其训练需要海量数据和强大的算力来支撑训练和推理过程,其中数据主要由服务器和光模块存储、运输,算力支撑则依赖各类芯片。
算力需求陡增,业界普遍认为,高性能芯片的短缺是限制国内大模型行业发展的重要因素。
但在腾讯看来,用上了先进芯片并不代表就拥有了先进算力,原因在于高性能计算存在“木桶效应”,一旦计算、存储、网络任一环节出现瓶颈,就会导致运算速度严重下降。
点击收藏本站,随时了解时事热点、娱乐咨询、游戏攻略等更多精彩文章。





















